ThinkStats (5)
朝の続きに着手。面白いです。
2.3 分布
データの分布をデータ構造として表現するために辞書を使ってらっしゃいます。ええと、登録の方法が例示されてまして以下。
hist = {}
for x in t:
hist[x] = hist.get(x, 0) + 1辞書の get メソドの第二引数は key が登録されてない場合のデフォな値を設定するんですね、成程。あと、正規化 (normalization) のソレも例示されてます。
n = float(len(t))
pmf = {}
for x, freq in hist.items():
pmf[x] = freq / n辞書#items() は key, value を戻すんですね。
2.4 ヒストグラムを表現する
とりあえず Pmf.py を取得。
$ wget http://thinkstats.com/Pmf.py
Pmf.hist#Items() が面白そうなのでちょっと確認。
>>> import Pmf >>> hist = Pmf.MakeHistFromList([1, 2, 2, 3, 5]) >>> for val, freq in hist.Items(): ... print val, freq ... 1 1 2 2 3 1 5 1
ふむふむ。ってことで演習問題に着手。ええと最頻値とは
統計学における最頻値またはモード(mode)とは、データ群や確率分布で最も頻繁に出現する値である
wikipedia 日本語版の最頻値 より引用
えーと、辞書を扱うメソドを確認した方が良いな。や、Pmf.py 見ないと駄目か。
とりあえず
Hist#Items() を使って地味にやってみます。戻すのは「最頻値」のリストで良いかな。ぶっちゃけてしまうと hist.Items() の key じゃない側で sort できれば良いのですが。ググッてみたらありました。
すばらです。ええと、hist.Items() は辞書じゃなくてリストのリストが戻ってくるのか。
>>> for x, y in sorted(hist.Items(), key=lambda x:x[1], reverse=True): ... print(x, y) ... (2, 2) (3, 2) (1, 1) (4, 1) (5, 1)
ええと、以下でリストが戻りました。
import Pmf
def Mode(hist):
list = []
for key, val in sorted(hist.Items(), key=lambda x:x[1], reverse=True):
if list == []:
list.append(key)
v = val
else:
if v == val:
list.append(key)
return listLisp/Scheme 式で list ってやれば戻る、って書き方するあたりがアレ。動作の確認が以下。
>>> import Pmf >>> import mode >>> hist = Pmf.MakeHistFromList([1, 2, 2, 3, 3, 4, 5]) >>> mode.Mode(hist) [2, 3]
このあたりも試験ドリブンで何とかならんかな。ちょい調べてみます。何かあれば追記するかも。
あった
以下とのこと。
試しに試験を書いてみました。
import Pmf
import mode
import unittest
class TestMode(unittest.TestCase):
def test_mono(self):
hist = Pmf.MakeHistFromList([1, 1, 1, 2, 3, 4])
result = mode.Mode(hist)
self.assertEqual([1], result)
def test_multi(self):
hist = Pmf.MakeHistFromList([1, 1, 2, 2, 3, 4])
result = mode.Mode(hist)
self.assertEqual([1, 2], result)
if __name__ == '__main__':
unittest.main()実行したら以下な出力。
$ python mode_test.py .. ---------------------------------------------------------------------- Ran 2 tests in 0.000s OK
すばらです。
む
もう少しあった。つうかこれは以下で良いはずだが他の方法がある模様。
>>> sorted(hist.Items(), key=lambda x:x[1], reverse=True) [(2, 2), (3, 2), (1, 1), (4, 1), (5, 1)]
ええと、以下な記述がありますね。
operator モジュールには itemgetter という関数があり、これを sorted へキーとして渡すことができます。
Think Stats より引用
ええと以下によれば
>>> from operator import itemgetter >>> sorted(hist.Items(), key=itemgetter(1), reverse=True) [(2, 2), (3, 2), (1, 1), (4, 1), (5, 1)]
むむ。これはこれは。
さらに追記
2.5 ヒストグラムを描画する、な節。うぶんつには以下なパケジがあるようです。
$ apt-cache search matplotlib python-matplotlib - Python based plotting system in a style similar to Matlab
導入して試験してみます。ってことで以下。
>>> import matplotlib.pyplot as pyplot >>> pyplot.pie([1, 2, 3]) >>> pyplot.show()
出力が以下。
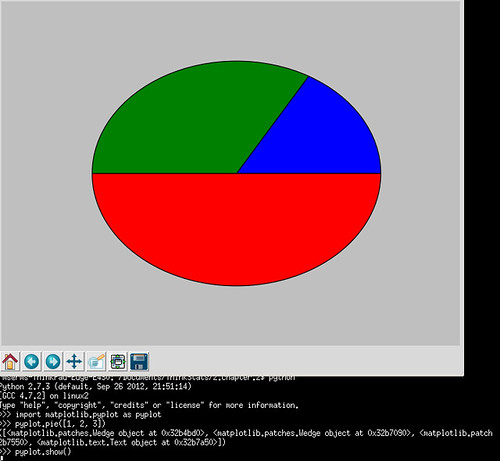
これはこれは、というカンジです。
とりあえず
妊娠期間のヒストグラム云々以降は明日ということにて。今日はもう限界。というか食器洗いをしなきゃ、だったりして。